其他技巧可以参考:http://www.letpub.com.cn/index.php?page=sci_writing
英语谓语动词时态共有16种,在英文科技论文中用得较为频繁的主要有三种:即一般现在时、一般过去时和将来时。正确地使用动词时态是科研写作的基本功,我们在撰写英文论文时,如不能正确选用时态,常常会改变文章所要表达的意思,从而影响评审专家与读者的理解。
一篇典型的科技论文有一个基本的框架结构:Abstract (综述科研背景,提出研究的问题和假设(hypothesis)),Materials and Methods (描述自己的研究方法),Results (分析所得的研究结果),Discussion (深入讨论研究结果的意义并简要指出将来的研究方向)。我们现根据这个论文框架,就一些规律性问题做些探讨,希望对大家有所帮助。
首先应该把握以下三个基本要点:
1、一般现在时:主要用于不受时间限制的客观存在事实的描述,或发生或存在于写论文之时的感觉、状态、关系等的描述或致谢的表述等。值得注意的是,出于尊重,凡是他人已经发表的研究成果作为”previously established knowledge”,在引述时普遍都用一般现在时。
2、一般过去时:用于写论文中作者自己所做工作的描述。例如描述自己的材料、方法和结果。
3、 一般将来时:用于撰写论文之后发生的动作或存在的状态。例如提出下一步的研究方向。
摘要(Abstract):
摘要反映我们自己的研究结果,一般采用过去时。
概述(Introduction):
(1)概述中的研究背景通常会引用相关学科中广为接受的原理或事实,以及你所做研究的重要性,这些通常采用现在时。
例如:Genomics provides crucial information for rational drug design.
(2)在概述中也可能引用与你从事项目相关的一些研究结果,为表达你对该研究结果仍坚信其正确性及相关性,即使已经是很久以前的研究结果,可使用现在时。
例如:Many of the lakes and wetlands in the region are located in craters or valleys blocked by early Pliocene lava flows (Ollier & Joyce, 1964).
Garcia (1993) suggested that under certain conditions, an individual’s deposit income is the same as the income from purchased national debt, thus changes in the amount of bank loans and deposits caused by changes in the amount of reserves will eventually affect the bond price.
- 需要注意的是如果引用的是一些已经过时或失效的科研结果,动词要使用过去时。
例如:Nineteenth-century physicians held that women got migraines because they were “the weaker sex,” but current research shows that the causes of migraine are unrelated to gender.
(注意这里从过去时态过渡到现在时态)
材料与方法(Materials and Methods):
对写论文之前自己所做工作的描述,通常采用一般过去时。
例如:(例1) Total phosphorous (TP) and total nitrogen (TN) were measured in the laboratory using standard procedures.
(例2)The standard protocol was followed for the preparation of the media from stock solutions.
结果(Results):
- 对自己得出的研究结果,采用过去时进行详细的阐述。
例如:(例1)Overall, more than 70% of the insects collected were non-phytophagous.
(例2) Following activation of NT oocytes with strontium, the cell cycle resumed in both groups.
- 描述图表内容通常采用现在时。
例如:(例1) Figure 1 displays the comparative variation in the morphology of donor chromatin in both age groups of oocytes.
(例2) Table 1 below shows the stream flows calculated for each stream using Equation 1.
图1和表1表达的论文写作时的状态,所以要用现在时。
讨论(Discussion):
- 采用现在时表达研究结果的意义。
例如:Removal of vegetation for agricultural purposes appears to negatively affect the water quality of streams.
- 采用过去时总结研究结果,并采用现在时对研究结果进行讨论与解释。
例如:(例1)Weight increased as the nutritional value of feed increased. These results suggestthat feeds higher in nutritional value contribute to greater weight gain in livestock.
(注意这里用过去时描述了实验发现,但在讨论这个发现的意义时用的是现在时。)
(例2)Leaf carbon and phenolic content did not differ across sites, indicating that the response of
secondary plant chemicals such as phenolics to water is complex.
(这句的描述几乎没有假设的意思,表示作者坚信其研究结果和结论的正确性及相关性)
结论(Conclusion):
可用多种时态,使用过去时强调过去的研究成果,并可采用现在时或将来时表达未来的研究方向或研究前景。
例如:Although the study found evidence of tillage and irrigation within the study area, from the data collected it was not possible to determine if the effects of agriculture upstream cause (or caused) higher levels of total nitrogen downstream. Further studies are therefore necessary to determine the effects of agriculture on the health of Stringybark Creek.
(转载请注明本文来自LetPub中文官方网站:http://www.letpub.com.cn/index.php?page=sci_writing_2)


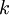 层网络简洁地表达出来(这里的简洁是指隐层单元的数目只需与输入单元数目呈多项式关系)。但是对于一个只有
层网络简洁地表达出来(这里的简洁是指隐层单元的数目只需与输入单元数目呈多项式关系)。但是对于一个只有 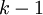 层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。
层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。